
Introduction
최근 프로젝트에서 최적화 작업을 담당하게 되었습니다. 최적화가 처음이라 어디서부터 시작해야할지 아예 감이 안잡혔습니다…
이 글은 제가 직접 박치기하면서 배운 유니티 최적화 방법들을 정리한 글입니다. 제가 직접 박치기 하면서 “이 코드가 왜 CPU 사용량을 많이 잡아먹는지”, “왜 GC.Alloc을 유발하는지” 원인을 분석해보고, 해결책을 찾아가면서 느꼈던 점들을 중심으로 작성했습니다.
Summary (주요 성능 개선 사항 (진행 중))
최적화 작업은 현재진행형이며, 약 1개월간의 초기 단계를 통해 다음과 같은 의미 있는 성능 개선을 이루었습니다.
CPU 병목 현상 완화: 게임 로직의 CPU 점유 시간을 평균 12ms에서 4.5ms로 단축하여, 부드러운 프레임 유지를 가능하게 했습니다.
메모리 할당(GC) 최적화: 프레임당 0.5MB(500KB) 이상 발생하던 가비지를 3.8KB로 99% 이상 감소시켰습니다. 이를 통해 GC(가비지 컬렉션)로 인한 프레임 스파이크를 원천적으로 방지했습니다.
주요 개선이 이루어질 때마다 관련 데이터를 업데이트하겠습니다.
Note
- Unity 6000.0.59f2 기준으로 작성되었으며, 다른 버전도 비슷할겁니다. 아마도?
- 현재 다른 작업으로 인해 글이 완성되지 않았습니다. 지속적으로 업데이트할 예정입니다.
Unity Profiler
일단 성능 최적화하기 전에 어디에서 성능 병목이 발생하는지 측정하고 분석하는 과정이 필요합니다. 유니티 에디터에서는 자체적으로 제공하는 Unity Profiler를 통해 CPU, GPU, Memory 사용량을 측정하고 분석할 수 있습니다.
How to Use Unity Profiler
일단 유니티 에디터 상단 메뉴에서 Window > Analysis > Profiler를 클릭하여 프로파일러 창을 엽니다.
저는 일단 CPU 최적화를 중심적으로 살펴보기 위해 CPU Usage의 Scripts, Garbage Collector 카테고리만 켜두고 나머지는 껐습니다.
Note
측정 시작/중지: 프로파일러 창 상단에 빨간 버튼을 눌러 시작/중지Clear: 프로파일러 분석한 데이터들을 초기화Deep Profile: 스크립트 내부 함수 호출까지 분석 (렉이 많이 발생하므로 주의) (비추천)공식 문서: Unity Profiler Window 참고
Tip
Others 카테고리는 에디터에서만 발생하는 오버헤드이므로 무시해도 됩니다.
Custom Profiler Markers
유니티 프로파일러는 기본적으로 유니티 엔진의 콜백 함수들 (Start, Update, FixedUpdate 등) 만 분석해주기 때문에
어떤 함수가 문제인지 찾기 어렵습니다. 이럴때는 ProfilerMarker
을 사용하여 그 부분만 자세하게 분석할 수 있습니다.
using Unity.Profiling;public sealed class TestProfilerMarker{ private void Update() { MyMethod1(); MyMethod2(); }
private static readonly ProfilerMarker myMarker1 = new ProfilerMarker("MyCustomMarker1"); private static readonly ProfilerMarker myMarker2 = new ProfilerMarker("MyCustomMarker2");
// 첫번째 방법 private void MyMethod1() { myMarker1.Begin(); // 측정하고 싶은 코드 myMarker1.End(); }
// 두번째 방법 private void MyMethod2() { using (myMarker2.Auto()) { // 측정하고 싶은 코드 } }}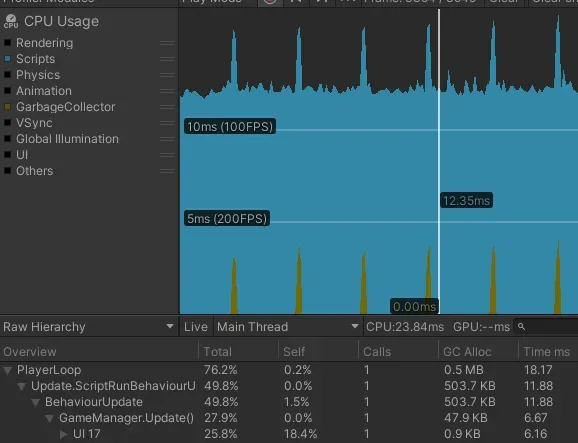 최적화 전 GameManager.cs에 넣은
최적화 전 GameManager.cs에 넣은 UI 17 마커
Explanation
Q. 그냥 Deep Profile 켜면 안되나요?
A. Deep Profile은 모든 함수 호출을 추적하기 때문에 렉이 심하게 발생하기 때문에 ProfilerMarker를 사용하여 필요한 함수만 선택적으로 분석하는 것이 좋습니다.
Explanation
Q. UI 17 마커는 뭐길래 CPU를 많이 사용해요?
A. 업데이트마다 계속 Canvas Alpha를 변경하고 있어서 그렇습니다. 이를 최적화하려면 값이 실제로 변경될 때만 업데이트하는 패턴을 사용하세요.
CPU Optimization
이제 Unity Profiler를 사용하여 어디가 문제인지 확인했으니 본격적으로 CPU 최적화를 해보겠습니다.
CPU 최적화를 하면 프레임이 잘 나와서 게임이 부드럽게 돌아가지만 메모리 사용량은 늘어납니다.
하지만 대부분 PC는 메모리는 충분히 크기 때문에 CPU 최적화를 우선적으로 하는 것이 좋습니다.
Dirty Flag Pattern
처음에 이걸 보고 ”?? 더러운 플래그 패턴??” 라고 생각했는데, 이 패턴은 변경할떄만 업데이트하는 디자인 패턴입니다. 저희는 개발자니 코드로 보여드리겠습니다.
using UnityEngine;public class DirtyFlagExample : MonoBehaviour{ [SerializeField] private Text curLeftBulletText;
public int curLeftBullet = 10; private int _prevBullet = -1;
private void Update() { // 이 코드는 매 프레임마다 Text를 변경합니다. curLeftBulletText.text = curLeftBullet;
// 이 코드는 변경 할때만 Text를 변경합니다. if (_prevBullet != curLeftBullet) // 이전 값과 현재 값 비교 { _prevBullet = curLeftBullet; curLeftBulletText.text = curLeftBullet.ToString(); } }}코드로 보면 더티 플래그 패턴은 이전 값을 캐시하고 현재 값과 비교하여 변경되었을 때만 업데이트하는 방식입니다. 이를 통해 불필요한 업데이트를 줄여 CPU 사용량을 크게 줄일 수 있습니다.
Tip
위 예시는 패턴 이해를 위해 Update에서 비교했지만, 실제로는 값이 변경되는 시점(Setter)에서 바로 처리하는 것이 더 효율적입니다.
using UnityEngine;public class DirtyFlagExample : MonoBehaviour{ [SerializeField] private Text curLeftBulletText;
public int curLeftBullet { get; private set; } = 10;
public void SetCurLeftBullet(int newBullet) { if (curLeftBullet != newBullet) // 변경되었을 때만 업데이트 { curLeftBullet = newBullet; curLeftBulletText.text = curLeftBullet.ToString(); } }}Caching
캐싱 (Caching)은 데이터 가져오는 비용이 비쌀 경우,
한 번만 가져와서 변수에 저장(캐시) 하고 필요할때마다 캐시해둔 변수를 사용하는 방법입니다.
아까 설명한 더티 플래그 패턴은 불필요한 실행을 줄이는 패턴이라면
캐싱은 불필요한 탐색을 줄이는 패턴입니다. (물론 더티 플래그 패턴도 캐싱의 일종이긴 합니다)
Component Caching
유니티에서 가장 비용이 많이 드는 작업 중 하나는 GetComponent, FindObjectsByType, Camera.main 처럼
씬에 있는 모든 오브젝트를 탐색 하는 작업입니다.
특히 이 함수들을 Update, FixedUpdate 같은 자주 호출되는 함수에서 사용하면 성능에 큰 영향을 미칩니다.
따라서 이러한 함수들은 Awake 또는 Start에서 한 번만 호출하여 캐싱하는 것이 좋습니다.
GetComponent를 예시로 설명해보겟습니다.
Danger (매 프레임마다 GetComponent 호출)
using UnityEngine;public class CachingExample1 : MonoBehaviour{ private void Update() { GetComponent<Rigidbody>().AddForce(Vector3.up * 10f); }}Solution (Awake에서 한 번만 GetComponent 호출하여 캐싱)
using UnityEngine;public class CachingExample2 : MonoBehaviour{ private Rigidbody _rb;
private void Awake() { _rb = GetComponent<Rigidbody>(); }
private void Update() { _rb.AddForce(Vector3.up * 10f); }}Explanation
Q. Camera.main은 왜 캐싱해야 하나요?
A. Camera.main은 유니티 엔진 C++의 FindMainCamera(C#의 FindGameObjectsWithTag("MainCamera")와 유사)를 호출하기 떄문입니다.
C++ and C# bridge
유니티는 엔진의 핵심 기능을 담당하는 C++ (Native) 코드와, 우리가 작성하는 C# (Managed) 코드라는 두 개의 다른 환경으로 이루어져 있습니다.
이 두 환경이 소통할때마다 브릿지를 건너야 합니다.
GetComponent, transform 같은 유니티 API를 호출할 때마다 이 브리지 오버헤드가 발생합니다.
따라서 캐시를 하여 브리지 오버헤드를 줄이는 것이 좋습니다.
using UnityEngine;public class TransformCachingExample : MonoBehaviour{ private Transform _cachedTransform;
private void Awake() { _cachedTransform = transform; }
private void Update() { _cachedTransform.position += Vector3.up * Time.deltaTime; }}Note (브릿지 건너는 비용이 비싼 이유)
Explanation (Managed/Native 경계 넘기 (Interop Call))
Unity API를 호출할때마다 Managed 영역에서 Unity Engine Native 영역으로 경계를 넘어갑니다
[사용자 코드 영역]
Mono: C# (JIT 컴파일)
IL2CPP: C++ (AOT 컴파일됨)
공통점: 둘 다
Managed 메모리 모델 사용, GC 존재↓
[경계] ← 여기가 문제!
↓
[Unity Engine C++ 영역]
Native 메모리, GC 없음
비용이 발생하는 이유는
- 호출 규약 전환: C# 스타일 호출 -> C++ 스타일 호출
- 안전성 검증: null 체크, 타입 검증, Unity Object 유효성 검사 등
- 실행 환경 전환: Managed 런타임 -> Native 런타임
Explanation (데이터 마샬링 (Marshalling))
브릿지를 건너는 비용 중 가장 큰 비중을 차지할 수 있습니다.
C#과 C++은 데이터를 메모리에 저장하는 방식(메모리 레이아웃)이 다르기 때문입니다.
하지만 모든 마샬링 비용이 비싼 것은 아니며, C#의 데이터 타입이 C++과 얼마나 호환되는지에 따라 비용이 달라집니다.
블리터블(Blittable) 타입C#과 C++의 메모리 레이아웃이 같아서 변환 없이 메모리 복사만으로 전달 가능한 타입
- 비용: 매우 낮음 (메모리 복사만 발생)
- 예시:
int,float,bool,Vector3,Quaternion- 과정: 단순 메모리 복사
논-블리터블(Non-Blittable) 타입C#과 C++의 메모리 레이아웃이 달라서 변환 작업이 필요한 타입
- 비용: 매우 높음 (변환 작업 발생)
- 예시:
string- 과정:
gameObject.name = "Enemy"
- 메모리 할당: C++ 네이티브 힙에 새 메모리 공간 할당
- 인코딩 변환: C#
string(UTF-16) → C++char*(UTF-8)- 복사: 변환된 데이터를 새 메모리 공간에 복사
- 포인터 전달: C++ 엔진에 새 메모리 주소 전달
- 해제: C++에서 사용 후 할당된 메모리 해제
Explanation (GC(Garbage Collector) 관련 작업)
C# 객체가 C++로 넘어갈 때 GC 안전성 처리가 필요합니다.
이떄 GC Pinning (메모리 고정)을 수행합니다.
byte[] data = new byte[1024 * 1024];
// 1. GC가 이 객체를 이동하지 못하도록 PIN 설정GCHandle handle = GCHandle.Alloc(data, GCHandleType.Pinned);
// 2. C++에 고정된 메모리 주소 전달IntPtr ptr = handle.AddrOfPinnedObject();
// 3. C++ 작업 완료후 PIN 해제handle.Free();GC Pinning의 문제점
GC 성능 저하: PIN 설정된 객체는 GC가 메모리 압축할때 이동할수 없어 메모리 단편화 발생오버헤드 발생: PIN 설정/해제 작업메모리 낭비: PIN된 객체는 GC가 최적화할수 없어 메모리 사용량 증가
Animation Key Hashing
Animator에서 애니메이션 상태를 전환할 때 문자열 이름을 직접 사용하는 것은 성능에 좋지 않습니다.
Animator.SetTrigger("Run")이나Animator.SetFloat("Speed", value)를 호출하면 다음 작업을 수행합니다.
- “Run”또는 “Speed” 문자열을 받고
해시(Hash)연산을 수행하여 int 값으로 변환- 해시된 int 값을 사용하여 실제 파라미터 값을 변경
Update에서 Animator.SetFloat을 호출하는 경우, 문자열 해싱 작업이 매 프레임마다 발생하여 성능에 좋지 않습니다.
따라서 Animator.StringToHash를 사용하여 id를 캐싱하고 재사용하는 방법을 사용합니다.
Danger (문자열 이름을 직접 사용)
private Animator _animator;
private void Awake(){ _animator = GetComponent<Animator>();}
private void Update(){ float speed = Input.GetAxis("Vertical"); _animator.SetFloat("Speed", speed); // 매 프레임마다 문자열 해싱 발생}Solution (Animator.StringToHash로 해시 캐싱)
private static readonly int SpeedHash = Animator.StringToHash("Speed");private Animator _animator;
private void Awake(){ _animator = GetComponent<Animator>();}
private void Update(){ float speed = Input.GetAxis("Vertical"); _animator.SetFloat(_speedHash, speed); // 해시를 사용하여 성능 최적화}Tip
동일한 애니메이션 파라미터를 여러곳에서 사용한다면, AnimHash 같은 별도의 클래스를 만들어서 관리하는 것도 좋은 방법입니다.
public static class AnimHash{ public static readonly int Speed = Animator.StringToHash("Speed"); public static readonly int Jump = Animator.StringToHash("Jump"); // 다른 해시들...}using UnityEngine;using static AnimHash; // AnimHash 클래스의 정적 멤버를 직접 사용
public class AnimatorHashingExample3 : MonoBehaviour{ private Animator _animator; private void Awake() { _animator = GetComponent<Animator>(); }
private void Update() { float speedValue = Input.GetAxis("Vertical"); _animator.SetFloat(Speed, speedValue); }}Distance Checks
Update나 FixedUpdate에서 두 오브젝트 간의 거리를 측정하는 것은 AI, 플레이어 감지, 트리거 등 많이 사용되는 로직입니다.
하지만 Vector3.Distance나 Vector2.Distance는 제곱근 연산이 포함되어 있어 비용이 많이 듭니다.
Note (제곱근 연산)
Vector3.Distance(a, b)는 내부적으로 Mathf.Sqrt를 호출하여 제곱근을 계산합니다.
제곱근 연산은 단순 덧셈/뺄셈/곱셈보다 훨씬 비용이 많이 듭니다.
Explanation
Q. 제곱근 연산이 왜 비싸요?
A. 제곱근은 한 번의 명령으로 계산할 수 없고, 반복적인 근사 알고리즘을 통해 값을 구하기 때문입니다.
예시로 뉴턴-랩슨 방법(Newton-Raphson method) 같은 알고리즘이 사용됩니다.
x_next = 0.5 * (x_current + n / x_current)
// √16을 구한다면:초기값 x0 = 4x1 = 0.5 * (4 + 16/4) = 4 // 정확!x2 = 0.5 * (4 + 16/4) = 4
// √10을 구한다면:초기값 x0 = 3x1 = 0.5 * (3 + 10/3) = 3.1666...x2 = 0.5 * (3.1666 + 10/3.1666) = 3.1623...x3 = 0.5 * (3.1623 + 10/3.1623) = 3.1622... // 거의 정확따라서 Distance 대신 SqrMagnitude를 사용하여 제곱근 연산을 피하는 것이 좋습니다.
Danger (Distance 사용)
[SerializeField] private float _detectionRange = 5f;private Transform _target;
private void Update(){ float distance = Vector3.Distance(transform.position, _target.position); if (distance < _detectionRange) { // 타겟 감지 }}Solution (SqrMagnitude 사용)
[SerializeField] private float _detectionRange = 5f;private Transform _target;private float _detectionRangeSqr;
private void Awake(){ _detectionRangeSqr = _detectionRange * _detectionRange;}
private void Update(){ float sqrDistance = (transform.position - _target.position).sqrMagnitude; if (sqrDistance < _detectionRangeSqr) { // 타겟 감지 }}Note (참고: 거리 연산 속도 비교)
sqrMagnitude가 Mathf.Sqrt를 사용하는 Distance에 비해 얼마나 빠른지, 그리고 다른 근사 계산법에는 어떤 것이 있는지 비교한 표입니다.
| 방법 | 상대 속도 | 정확도 | 반환값 | 사용 케이스 |
|---|---|---|---|---|
| sqrMagnitude | 1x | 100% | 거리² | 거리 비교만 필요할 때 |
| 빗변 근사식 (옥타곤) | 2-3x | 92% | 근사 거리 | 정확도가 덜 중요한 거리 계산 |
| Fast Inverse Sqrt | 5-8x | 99.9% | 1/거리 | 정규화 벡터 계산 |
| Mathf.Sqrt | 10-15x | 100% | 정확한 거리 | 정확한 거리 값 필요 |
C#‘s Null Checks
if (myObject == null) C#에서 null을 체크하는 이 코드는 유니티에서는 단순한 코드가 아닙니다.
유니티의 GameObject, Transform 등 UnityEngine.Object를 상속받는 객체들은 C#과 C++ 양쪽에 존재합니다.
Destory(myObject)를 호출하면 C++ 객체는 파괴되지만 C# 래퍼 변수는 null이 아닙니다. 이 상태를 가짜 null(fake null) 이라고 부릅니다.
유니티에서는
==연산자를 오버로딩(overloading)하여,if (myObject == null)을 실행하면 두가지를 검사합니다.
- C# 객체가 실제로 null인지 (C# null 체크)
- C++ 브릿지를 건너가서 C++ 객체가 파괴 되었는지 (유니티의 가짜 null 체크)
이 가짜 null 체크는 C++와 C#의 브릿지 오버헤드를 발생시키므로 성능에 좋지 않습니다.
따라서 만약 C# null인지 궁금할떄는 Object.ReferenceEquals(myObject, null) 또는 myObject is null 패턴을 사용하면 됩니다.
Tip (이미 == null은 최적화 적용되있음)
사실 유니티에서는 == null을 실행할때 필요할때만 가짜 null 체크 수행하도록 최적화 되어있습니다.
따라서 그냥 평범한 상황일때는 == null을 사용해도 됩니다.
private static bool CompareBaseObjects(Object lhs, Object rhs){ bool flag1 = (object) lhs == null; bool flag2 = (object) rhs == null;
// 1. C# null 체크 if (flag2 & flag1) return true;
// 2. 가짜 null 체크 if (flag2) return !Object.IsNativeObjectAlive(lhs); return flag1 ? !Object.IsNativeObjectAlive(rhs) : lhs.m_InstanceID == rhs.m_InstanceID;}Data Structures & Logic
어떤 자료구조를 선택하고 데이터를 어떻게 접근하느냐에 따라 CPU 캐시 적중률과 명령어 처리 속도가 크게 달라집니다.
Array vs List
List<T>는 내부적으로 배열을 감싸고 있습니다.
인덱서(’[]‘)를 통해 접근할때마다 함수 호출 비용과 유효성 검사가 발생합니다.
극한의 최적화가 필요한 Hot Path (매 프레임마다 실행되는 코드)에서는 Array를 사용하는것이 좋습니다.
Note (진짜 차이가 있을까?)
JIT 컴파일러 최적화 때문에 차이는 미미합니다.
-
함수 호출 비용:
List[i]는 메서드 호출 (get_Item)이지만, JIT가 인라인 처리하여 기계어 수준에서는 직접 접근으로 변경됩니다. 즉, 함수 호출 오버헤드가 거의 없습니다. -
유효성 검사:
List[i]는 접근할때마다if (index >= _size)검사를 수행합니다.Array또한 경계 검사를 하지만, CLR 레벨에서 배열 검사가 훨씬 강력하게 최적화(Loop Cloning등)되어 있어 리스트보다 빠릅니다.
Dictionary Key Optimization
struct를 Key로 쓸 때 IEquatable<T>를 구현하지 않으면 .NET은 기본 비교 방식(ValueType.Equals)을 사용합니다.
기본 비교 방식은 리플렉션(Reflection) 을 사용하여 성능이 느립니다.
이때 int, float 같은 Blittable 타입일떄는 비트 단위 비교(Bitwise)로 최적화를 시도하지만,
참조 타입(string 등)이 하나라도 섞이면 리플렉션(Reflection)으로 돌아갑니다.
게다가 최적화 여부와 상관없이 박싱(Boxing) 문제는 계속 발생합니다.
Danger (기본 Struct 사용 (리플렉션 발생))
struct GridPos { public int x, y; }
// GetHashCode/Equals 미구현 시, 내부적으로 Reflection을 사용하여 비교함Dictionary<GridPos, Item> items;Solution (IEquatable 구현 (최적화))
struct GridPos : IEquatable<GridPos>{ public int x, y;
// 이 함수가 있어야 리플렉션을 안 쓰고 직접 비교함 public bool Equals(GridPos other) => x == other.x && y == other.y; public override int GetHashCode() => HashCode.Combine(x, y);}Data Locality (Struct vs Class)
CPU는 메모리에서 데이터를 가져올때 하나씩 가져오지 않고 캐시 라인(cache line, 보통 64바이트) 단위로 가져옵니다.
이떄 우리가 사용할 데이터들이 메모리에 연속적으로 배치되어 있으면 캐시 적중률이 높아져 성능이 좋아집니다.
Class Array
배열에는 몬스터의
주소(참조)만 들어있습니다. 실제 데이터는 힙 메모리 여기저기에 흩어져 있어, 접근할 때마다메모리 점프(Pointer Chasing)가 발생하고캐싱 미스(Cache Miss)가 일어납니다.
Struct Array
데이터 자체가 배열 안에 연속적으로 꽉 차 있습니다. CPU 캐시에 매우 친화적입니다.
데이터 개수가 많고 자주 순회해야 한다면, Class 대신 Struct 배열을 사용하는것이 좋습니다.
Explanation (구조체 배열도 완벽하지 않다 (AoS vs SoA))
구조체 배열을 사용하면 메모리가 연속되므로 클래스보다 빠르지만, 여전히 낭비가 존재할 수 있습니다. 이를 AoS (Array of Structures) 방식이라고 합니다.
만약 MonsterData에 HP, MP, Position, Name 등 필드가 많은데, 루프에서는 HP만 깎는다고 가정해 봅시다.
Example (AoS)
CPU는 캐시 라인(64byte)을 채우기 위해 지금 필요 없는 MP, Name 데이터까지 읽어옵니다.
// AoS: 일반적인 객체지향 방식 (캐시에 불필요한 필드도 로딩됨)struct Enemy { public int hp, mp; public string name; public Vector3 position; }Enemy[] enemies;
for (int i = 0; i < enemies.Length; i++){ enemies[i].hp -= 10; // 매번 캐시 라인에 불필요한 필드도 로딩됨}Example (SoA)
데이터를 필드별로 별도 배열로 쪼갭니다. HP 배열을 순회하면 캐시 라인에는 오직 HP 데이터만 꽉 차게 되므로 캐시 효율이 매우 좋아집니다.
// SoA: 데이터 지향 설계 (필요한 데이터만 캐시에 로딩됨)int[] enemyHps;int[] enemyMps;string[] enemyNames;Vector3[] enemyPositions;
for (int i = 0; i < enemyHps.Length; i++){ enemyHps[i] -= 10;}Note (Struct 크기와 복사 비용)
구조체는 값 타입(Value Type) 이므로 함수 인자로 넘기거나 변수에 할당할 때 값이 통째로 복사(Deep Copy) 됩니다.
과거 마이크로소프트 가이드라인에는 “16바이트를 넘으면 클래스를 고려하라”는 말이 있었지만, 최근에는 기준이 조금 다릅니다.
- 단일 객체 전달: 16~24바이트가 넘어가는 큰 구조체를 함수 인자로 넘기면, 단순히 주소(8바이트)만 넘기는 클래스보다 복사 오버헤드가 커서 느려질 수 있습니다.
- 배열 관리: 데이터가 크더라도, 수천 개를 배열로 관리해야 한다면 구조체가 압도적으로 유리합니다. (GC Alloc 0, 캐시 적중률 상승)
Tip (복사 비용 해결: ref와 in 키워드)
구조체 크기가 커서 복사 비용이 걱정된다면, ref(참조 전달)나 in(읽기 전용)을 사용하여 해결할수 있습니다.
복사 없이 원본의 주소만 참조하므로 클래스만큼 가볍게 전달할 수 있습니다.
struct BigData{ // 40바이트짜리 무거운 구조체 int a, b, c, d, e, f, g, h, i, j;}
// Bad: 값이 통째로 복사됨 (40바이트 복사 발생)public void ProcessData(BigData data) { ... }
// Good: 참조만 전달됨 (포인터 크기만큼만 비용 발생, 복사 없음)public void ProcessData(in BigData data) { ... }Warning (수정의 불편함)
구조체는 값 타입이므로 List<struct>에 들어있는 값을 직접 수정하기 번거롭습니다.
list[0].hp = 10은 컴파일 에러가 나서 복사본을 만든다음 수정을 하고 다시 할당해야합니다.
따라서 구조체는 주로 불변(Immutable) 데이터나 배열(Array) 환경에서 사용하는 것이 가장 좋습니다.
Switch vs If-Else
분기가 많아질수록 switch는 if-else보다 성능이 매우 좋습니다.
| 방식 | 작동 원리 | 시간 복잡도 | 특징 |
|---|---|---|---|
| If-Else | 선형 탐색 (Linear Scan) | 위에서부터 하나씩 검사. 조건이 많을수록 느림. | |
| Switch (연속O) | 점프 테이블 (Jump Table) | 값들이 모여있을 때 사용. 계산 한 번으로 주소 점프. | |
| Switch (연속X) | 이진 탐색 (Binary Search) | 값들이 흩어져 있을 때 사용. 범위를 절반씩 좁힘. |
switch (state){ case 0: Run(); break; case 1: Jump(); break; case 2: Attack(); break; // ... case 100: Die(); break; // If-else 였다면 100번 비교해야 도달함 // Switch는 O(1)로 즉시 실행}Tip
분기가 3~4개 미만이라면 if-else와 switch의 차이는 없습니다.
하지만 분기가 수십 개 이상 되는 로직에서는 반드시 switch를 사용하는것이 좋습니다.
Sealed Class
C#의 virtual 메소드나 인터페이스 호출은 런타임에 가상 함수 테이블(vtable) 을 조회(Lookup)해야 하므로 일반 함수보다 느립니다.
더 이상 상속되지 않는 클래스라면 sealed을 붙이는것이 좋습니다.
sealed를 붙이면 유니티의 IL2CPP 컴파일러가 “이 함수는 오버라이딩 될 리 없다”고 판단하여 Devirtualization(가상화 제거) 및 Inlining(인라인) 최적화를 수행합니다.
// IL2CPP가 Move() 함수를 직접 호출(Direct Call)로 최적화함public sealed class PlayerMovement : MonoBehaviour{ public void Move() { ... }}Memory (GC) Optimization
GC Alloc
GPU Optimization
Unity Engine Deep Dives
Afterword
이 글이 유니티 최적화에 관심있는 분들께 도움이 되었으면 좋겠습니다. 여기에 안 나온 최적화 팁이나, 더 좋은 방법이 있다면 유니티 최적화 토론에 공유해 주세요!
Sources: